- it’s (relatively) easy to set-up (usually almost no reverse-engineering knowledge required),
- it generalizes easily (similar approach can be used for every spambotnet, for example),
- it’s stable (bot protocol updates doesn’t break analysis environment).
- a lot of computing power is required – we want to track every known config simultaneously and that would require dozens of virtual machines for every major family,
- unless additional precautions are taken, sandboxed malware can still do harm to others – for example by being a proxy or sending spam. This is very complicated from a legal point of view,
- not every change is visible immediately. Spam and C&C addresses can easily be tracked, but new malware samples, injects and configuration changes are hard to track behaviorally.
- it’s relatively lightweight – even low-grade virtual server can track more than 300 bots without a problem,
- no malicious traffic is sent – commands from C&C are received, analyzed (for example new samples are downloaded) and ultimately ignored,
- usually, all commands are received without delay, so we know about botnet updates very soon.
- spam email templates,
- malicious samples downloaded from spam,
- peers’ IP addresses.
High-level overview
CERT Polska collaborates in SISSDEN (Secure Information Sharing Sensor Delivery event Network) project. One of its goals is to create feeds of actionable security information, that will be further processed by relevant entities (like security and academic researchers, CERTs, LEAs etc.).
Mtracker is going to be one of the sources of this intel (among honeypots, sandboxes and similar systems). During last few years we’ve reverse engineered a lot of various malware families and we often have a deep understanding of their inner workings and communication protocols. Because of that, we can mimic them during communication with C&C server and download new samples or webinjects automatically, without any delay or human intervention.
Motivation
The typical approach to an analysis of malware network traffic and communication is executing it in a controlled environment (like a long-term dedicated sandbox) and observing its behavior through a large set of filters, analyzers and monitors.
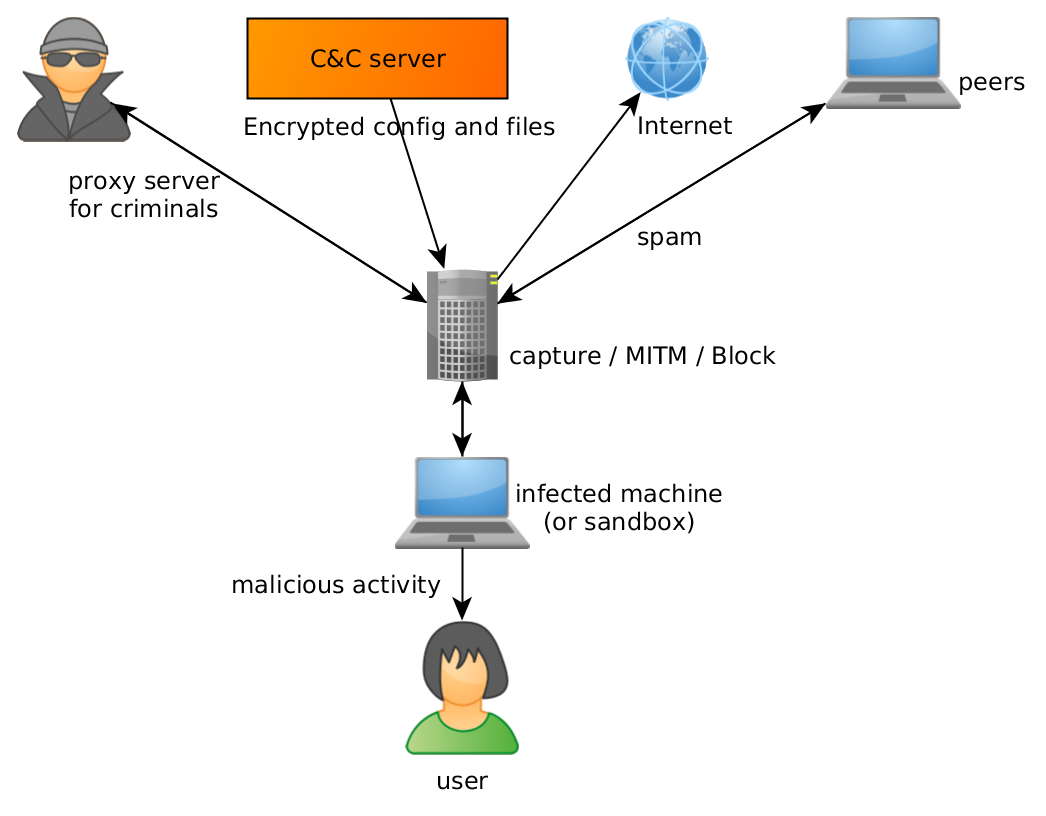
This approach has a lot of benefits:
Unfortunately, it’s not perfect:
Some of these problems can be resolved (for example by throttling network connection or blocking outgoing SMTP connections), but some are inherent to the approach.
We solved this problem differently:
![]()
We have a deep knowledge about malware communication protocols (thanks to our proactive research in this regard), so we decided that we can reimplement networking stack of a few chosen malware families and communicate with them directly.
This approach has a lot of benefits because it solves mentioned problems immediately:
A huge disadvantage of this method is a large amount of work required for reverse engineering, initial implementation and maintaining scripts for every family. Stability is also a problem (routine malware updates can break network protocols).
Architecture
Everything has begun as a set of loosely-related scripts, designed to download webinjects from banker trojan C&C’s. Back then everything was simple:
![]()
We have started with a static malware configuration extractor called ripper – one of our older projects. It’s able to extract hardcoded configuration from malware samples (for example: C&C server URLs, encryption keys etc). This was usually enough to start communication with malware and we used this data to semi-automatically download webinjects from known campaigns.
Everything was working great for a while, but our hunger for new knowledge grew and we noticed that we can easily adapt our system to download new malware samples at the same time (as malware usually receives updates through the same channel as other commands). This resulted in following “entangled” architecture:
![]()
This experiment turned out very well, so we went further in that direction. Our focus shifted to P2P botnets and spam at that time so we started to store more and more information:
![]()
At this point, we were generating quite a lot of traffic and we started being banned/blacklisted from a lot of botnets. Partially because of a large number of requests being done, but probably also because of occasional sloppiness on our part (like using the same bot_id all the time or hardcoding various fingerprints to constant values).
Being blacklisted is nothing new for us (anecdotally, long time ago we managed to accidentally put a whole NASK ISP network on a Zeus blacklist (!)). But in this case, due to a relatively big scale of operation, being “unbanned” wasn’t easy, even after fixing our code. Because of this, we had to do start using proxies which complicated our architecture a lot:
![]()
All configs are now being tracked from a few different proxies independently. This also allowed us to solve a problem of geolocalised campaigns – it’s very common that malware sample checks its location and refuses to infect computers outside of its target zone (most notable example is Dridex) or have a different set of injects/modules for every country (for example Emotet). Additionally, sometimes C&C servers are kept in the Tor network, so they can be reached only through a Tor proxy.
The final change (so far) that we introduced to our system is augmenting DNS. Using .bit (namecoin) TLDs is getting more popular with malware creators recently and if we want to support them we need to provide our own DNS resolver (.bit domains are not present in root TLD zone). After implementing this feature, we noticed another opportunity – sometimes C&C domains are taken down soon after campaign start, but the server is still working and responding to its original IP address. So when a domain fails to resolve (or resolves to a sinkholed domain) we’re using data from our passive DNS instead:
![]()
Last, but not least, an important part of the project is a web UI used to orchestrate, monitor and analyze results of the engine.
![]()
Results
In some sense, this is a conclusion of a lot of other projects. We have a few systems which collect raw data, and they are combined as inputs to mtracker to produce actual actionable information (like webinjects, spam templates, malicious IPs etc).
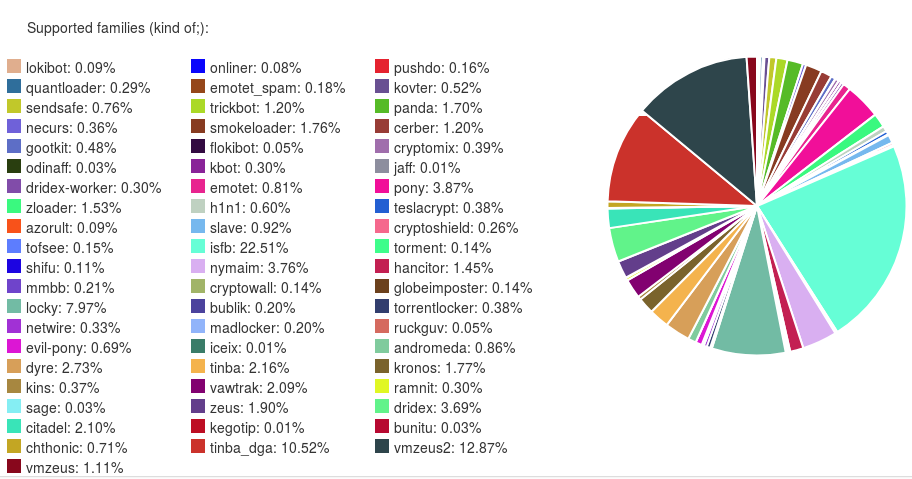
Most important source of information for us is the ripper and static configurations that can be used to track C&Cs. We have analyzed and can extract configurations from quite a lot of malware families. Percentage of distinct configurations by malware family that we have received:
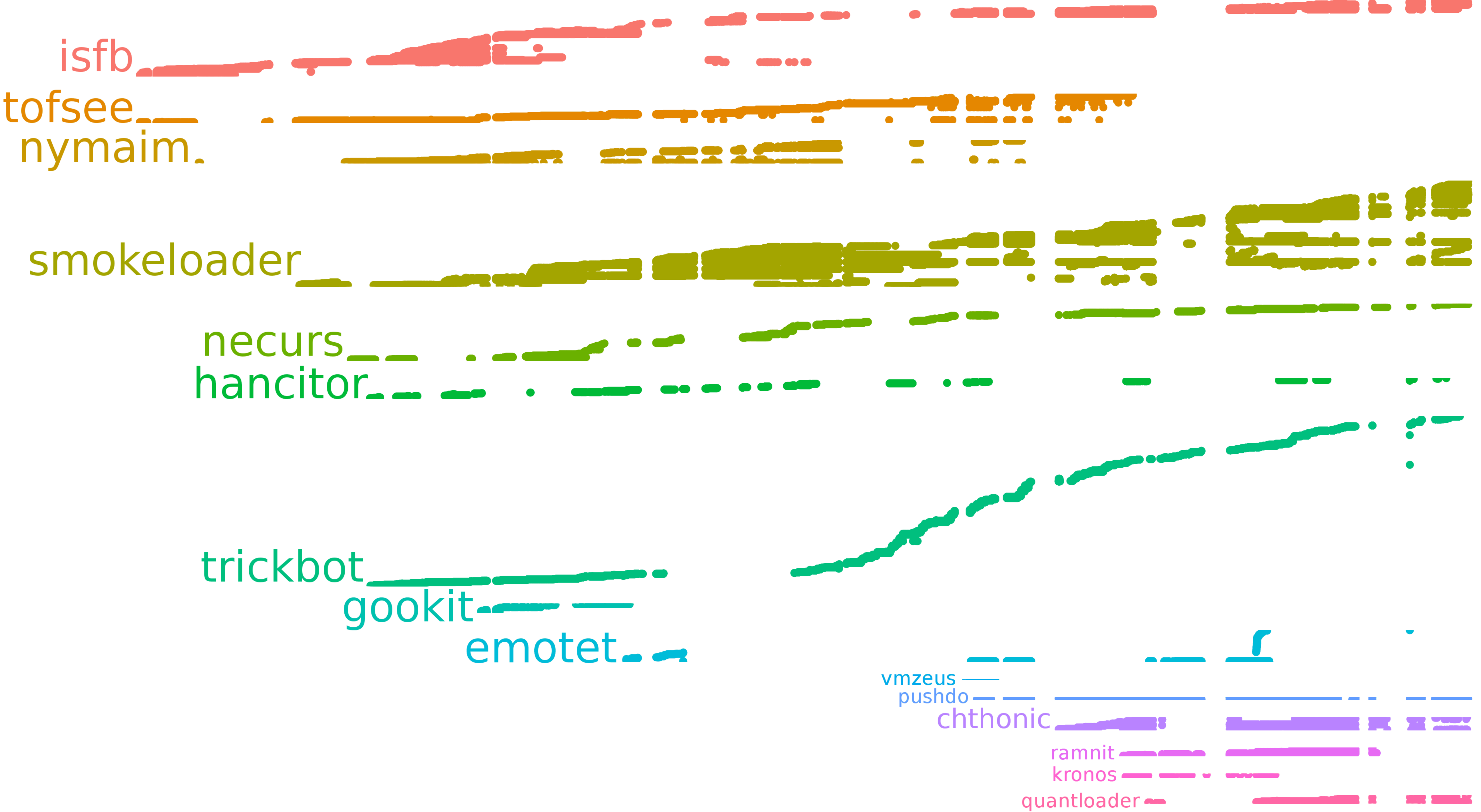
Of course, not all of these families were active all the time. A better overview of tracked malware history is given by the next image (time “flows upwards”, configs grouped by family):

In theory, we could track all these families, but due to a lot of reasons (like limited funding and time) we only focused on a few of them. History of successful config downloads (grouped by family) is shown below:

Or in extended form (successful config downloads grouped by content, grouped by family):