
Ostatnio natknęliśmy się na bardzo dobry artykuł o funkcjonowaniu kolejnej instancji botnetu Kelihos. Z zestawienia wyników badań prowadzonych przez autora tego artykułu wynika, że większość maszyn biorących udział w schemacie fast-flux tego botnetu znajduje się na terenie Polski. Postanowiliśmy więc dokładniej przyjrzeć się dostępnym próbkom tego złośliwego oprogramowania i podzielić się naszymi spostrzeżeniami.
Kelihos.B
Na początek krótko scharakteryzujmy opisywany botnet. Jest to kolejny (B) wariant znanego botnetu spamującego. Instancja składająca się z maszyn zainfekowanych wariantem A (będziemy nazywać ją Kelihos.A) tego złośliwego oprogramowania została rozbita przez zespoł pracowników Microsoftu, Kaspersky Lab. i Kyrus Tech we wrześniu ubiegłego roku. Kelihos posiada kanał CC, poprzez który odbiera rozkazy od botmasterów. Ktokolwiek posiada do niego dostęp (jest właścicielem kanału), ten kontroluje ten potężny botnet. W przypadku Kelihos.A kanał CC składał się z dwóch, części (podkanałów): sieci P2P oraz zestawu serwerów WWW. Zespół zwalczający Kelihos.A zaatakował jednocześnie oba te podkanały. Za pomocą pewnej odmiany ataku Sybil udało się wprowadzić fałszywe tożsamości do sieci P2P, które rozprowadziły wśród botów spreparowane informacje na temat serwerów z drugiego podkanału. W ten sposób udało się przejąć kontrolę nad oboma podkanałami, nie dając czasu aktualnym botmasterom na zaktualizowanie oprogramowania botów i zbudowanie nowego kanału. Zespół faktycznie przejął kontrolę nad botnetem i przekierował zapytania o rozkazy do tzw. sinkhole’a (czyli najprawdopodobniej zapytania te są ignorowane, lub wydawany jest rozkaz pozostawania w bezczynności). Botnet odkryty na przełomie stycznia i lutego tego roku (Kelihos.B) jest nowy i posiada oddzielny, własny kanał CC.
Podczas naszej analizy bota Kelihos.B, elementu kolejnej instancji botnetu Kelihos, natrafiliśmy na ciekawe zabezpieczenie, które zdecydowaliśmy się opisać w tym artykule.
Wyjątek
W trakcie debugowania programu bota główny wątek wygenerował wyjątek 0xc0000005 – naruszenie praw dostępu (ang. Access Violation) 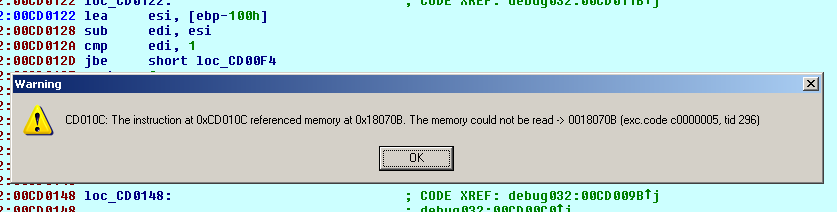 , który uniemożliwił kontynuowanie wykonania programu. Generowanie (w żargonie: rzucanie) wyjątków jest sposobem komunikacji części programu z innymi częściami – oraz z procesorem i systemem operacyjnym. W ogólnym znaczeniu wyjątek to sygnał, który jest przekazywany do aplikacji, kiedy nastąpiło jakieś zdarzenie wymagające jej uwagi (wyjątkowa sytuacja). Wyobraźmy sobie sytuację, kiedy procesor napotyka instrukcję dzielenia przez zero. Co powinien zrobić? Nie może wykonać tej instrukcji, ma natomiast do dyspozycji kilka innych możliwości. Może zignorować tą instrukcję i przystąpić do wykonania kolejnej. Jednak w w konsekwencji niemal na pewno nastąpią kolejne błędy. Może zatrzymać się – co oznacza zawieszenie całego systemu operacyjnego i poinformowanie o błędzie użytkownika – tzw. bug check (czyli na przykład dobrze znany użytkownikom starszych wersji systemu Windows Blue Screen) lub po prostu wyłączenie komputera. Jest też trzecie wyjście: procesor może zatrzymać się przy tej instrukcji, powiadomić oprogramowanie o wyjątkowej sytuacji i zapytać się, co powinien zrobić. W ten właśnie sposób funkcjonuje obsługa wyjątków (ang. exception handling). System operacyjny wykorzystuje mechanizmy przerwań procesora, by udostępnić programiście elastyczny sposób radzenia sobie z takimi wyjątkowymi sytuacjami. Procesor może wygenerować przerwanie (można je uznać za prymitywną formę wyjątku), które najpierw jest przekazywane do systemu operacyjnego. System operacyjny sprawdza, czy powinien sam obsłużyć to przerwanie (dzieje się tak w przypadku m.in. większości przerwań sprzętowych), czy też powinien przekazać informację o nim do aplikacji, do której należy wykonywany w trakcie przerwania kod. Jeśli zdecyduje się na to drugie wyjście, generuje wyjątek i przekazuje go do aplikacji. Programista w swojej aplikacji może zainstalować cały szereg (łańcuch) procedur obsługi wyjątków. Mogą one przekazywać wyjątek pomiędzy sobą oraz zdecydować o wykonaniu innych części programu, które będą stanowić rozwiązanie problemu. Jeśli żadna z procedur nie potrafi rozwiązać wyjątkowej sytacji, wyjątek zostanie przekazany z powrotem do systemu operacyjnego (wywołanie kernel32!UnhandledExceptionFilter), a ten z kolei zakończy działanie aplikacji.
, który uniemożliwił kontynuowanie wykonania programu. Generowanie (w żargonie: rzucanie) wyjątków jest sposobem komunikacji części programu z innymi częściami – oraz z procesorem i systemem operacyjnym. W ogólnym znaczeniu wyjątek to sygnał, który jest przekazywany do aplikacji, kiedy nastąpiło jakieś zdarzenie wymagające jej uwagi (wyjątkowa sytuacja). Wyobraźmy sobie sytuację, kiedy procesor napotyka instrukcję dzielenia przez zero. Co powinien zrobić? Nie może wykonać tej instrukcji, ma natomiast do dyspozycji kilka innych możliwości. Może zignorować tą instrukcję i przystąpić do wykonania kolejnej. Jednak w w konsekwencji niemal na pewno nastąpią kolejne błędy. Może zatrzymać się – co oznacza zawieszenie całego systemu operacyjnego i poinformowanie o błędzie użytkownika – tzw. bug check (czyli na przykład dobrze znany użytkownikom starszych wersji systemu Windows Blue Screen) lub po prostu wyłączenie komputera. Jest też trzecie wyjście: procesor może zatrzymać się przy tej instrukcji, powiadomić oprogramowanie o wyjątkowej sytuacji i zapytać się, co powinien zrobić. W ten właśnie sposób funkcjonuje obsługa wyjątków (ang. exception handling). System operacyjny wykorzystuje mechanizmy przerwań procesora, by udostępnić programiście elastyczny sposób radzenia sobie z takimi wyjątkowymi sytuacjami. Procesor może wygenerować przerwanie (można je uznać za prymitywną formę wyjątku), które najpierw jest przekazywane do systemu operacyjnego. System operacyjny sprawdza, czy powinien sam obsłużyć to przerwanie (dzieje się tak w przypadku m.in. większości przerwań sprzętowych), czy też powinien przekazać informację o nim do aplikacji, do której należy wykonywany w trakcie przerwania kod. Jeśli zdecyduje się na to drugie wyjście, generuje wyjątek i przekazuje go do aplikacji. Programista w swojej aplikacji może zainstalować cały szereg (łańcuch) procedur obsługi wyjątków. Mogą one przekazywać wyjątek pomiędzy sobą oraz zdecydować o wykonaniu innych części programu, które będą stanowić rozwiązanie problemu. Jeśli żadna z procedur nie potrafi rozwiązać wyjątkowej sytacji, wyjątek zostanie przekazany z powrotem do systemu operacyjnego (wywołanie kernel32!UnhandledExceptionFilter), a ten z kolei zakończy działanie aplikacji.
Niektórzy programiści (nie tylko twórcy botnetów) wykorzystują system wyjątków do zabezpieczania swoich programów przed różnego rodzaju analizą (botmaster chroni kod przed służbami prawa, autor gry komuterowej chroni ją przed crackerem). Instalują oni w swojej aplikacji procedurę obsługi wyjątku, w której zawieraja ważne dla wykonania programu instrukcje. Na przykład, procedura obsługi wyjątku powinna zostać przeprowadzona, aby gra się uruchomiła. Następnie wywołują oni specjalnie błąd, który zostanie obsłużony i w konsekwencji zostanie uruchomiona zainstalowana procedura (tak, jak miało to miejsce w przypadku bota Waledac). Poniższy kod przedstawia instalację procedury obsługi wyjątku:
push esi
push dword ptr fs:[0]
mov dword ptr fs:[0], esp
Następnie program wywołuje wyjątek, np. próbę odczytu pamięci z pod adresu 0:
mov eax, [eax]
Po wykonaniu tej instrukcji, procesor wygeneruje przerwanie, które w postaci wyjątku zostanie przekazane do aplikacji. Aplikacja uruchomi procedurę obsługi exception_handler i wykona zabezpieczone instrukcje.
Schemat ten można wykorzystać do ochrony kodu na wiele sposobów. Kiedy do analizowanego przez nas bota przekazano wyjątek błędu dostępu do pamięci, jako doświadczeni analitycy od razu rozpoczeliśmy przeglądać listę zainstalowanych procedur obsługi wyjątków, aby je przeanalizować. Jednak lista była pusta =). Po przekazaniu wyjątku do aplikacji ta przekazywała go z powrotem do systemu operacyjnego, który kończył jej działanie (dodatkowo brak rejestracji procedur VEH i domyślny UnhandledExceptionFilter). Zdaliśmy sobie sprawę, że jest to bardziej wyrafinowane zabezpieczenie i aby móc kontynuować nasze badania, musimy się mu dokładnie przyjrzeć.
Zabezpieczenie
Najpierw spójrzmy na instrukcję, która wywołała wyjątek: lodsw
Jest to próba uzyskania dostępu do obszaru pamięci, który nie został udostępniony dla analizowanej aplikacji. Na pierwszy rzut oka wygląda na zwyczajny błąd, może ze względu na niekompatybilność z systemem operacyjnym lub uszkodzenie kodu. Jednak porównaliśmy wykonanie programu z podłączonym debuggerem z wykonaniem bez debuggera. W przypadku odłączonego debuggera program działa poprawnie, łączy się z innymi członkami sieci P2P, zgłasza się do serwerów CC po rozkazy i rozpoczyna wysyłanie spamu 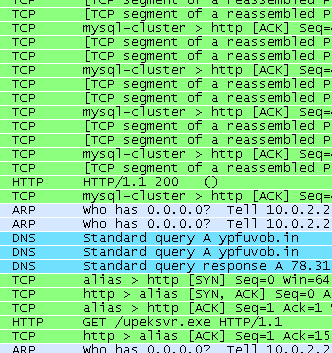
 . A więc wykonanie programu jest uzależnione od zmian wprowadzanych przez debugger.
. A więc wykonanie programu jest uzależnione od zmian wprowadzanych przez debugger.
Zabezpieczenie tu udaje błąd, a zabezpieczenia udające błędy są najbardziej wyrafinowane. W chronionym programie można zawrzeć różnego rodzaju procedury zabezpieczające, sprawdzające hasła i numery seryjne lub nawet klucze sprzętowe. Jednak, mimo iż są one ukryte przed zwykłym użytkownikiem, dla analityka uzbrojonego w swoje narzędzia są one widoczne, a ich ominięcie wymaga jedynie zmiany wartości rejestru lub flagi procesora. Ale kiedy zabezpieczenie jest przebrane za błąd wykonania, sprawy mają się dużo gorzej. W takim przypadku często potrzeba dotrzeć do źródeł błędu, które mogą znajdować się w zupełnie innym miejscu programu, mogą być wprowadzane w skomplikowanej konstrukcji logicznej aplikacji, hierarchi pętli sterujących i instrukcji warunkowych oraz przede wszystkim bardzo uzależnionych od środowiska wykonania programu. Na przykład w naszym przypadku błąd jest generowany przez zmiany wprowadzone przez debugger do środowiska wykonania aplikacji, co udowodniliśmy za pomocą prostego testu – uruchomienia bota z debuggerem i bez. Niektóre rodzaje zabezpieczeń podnoszą ten schemat do poziomu matematycznej funkcji kodu zależnej od środowiska – kodu zaszyfrowanego elementami środowiska. Aby zrozumieć ten mechanizm musimy dotrzeć do zmian wprowadzanych w środowisku przez debugger. A tych jest wiele: flagi stert, flagi środowiskowe, kody błędów, etc..
Przyjrzyjmy się jeszcze raz instrukcji lodsw. Powoduje ona załadowanie słowa z pod adresu wskazywanego przez rejestr ESI do AX. A skąd w ESI znalazł się zły adres?
Oto kontekst wykonania tej operacji:
mov edx, [edx+0Ch] ; [2]
mov edx, [edx+0Ch] ; [3]
mov ebx, edx ; [4]
jmp short addr_1
loop_1:
mov edx, [edx] ; [8]
cmp edx, ebx
jz short addr_6
addr_1:
mov esi, [edx+30h] ; [5]
lea edi, [ebp-100h]
mov ecx, 100h
or esi, esi
jz short loop_1
loop_2:
lodsw ; [6] Access Violation
cmp al, 41h
jb short addr_3
cmp al, 5Ah
ja short addr_3
sub al, 0E0h
addr_3:
stosb
or al, al
jz short addr_4
dec ecx
jz short loop_1
jmp short loop_2
addr_4:
lea esi, [ebp-100h]
sub edi, esi
cmp edi, 1
jbe short loop_1
push 0
push esi
call near ptr addr_5
cmp eax, [ebp-104h]
jnz short loop_1 ; [7]
ESI w momencie wykonania operacji [6] zawiera wartość załadowaną w instrukcji [5]. Ta wartość została pobrana z pod adresu wskazywanego przez EDX + 0x30. Tego rodzaju arytmetyka wskaźników jest stosowana do odwołań do pól struktur danych (początek struktury wskazuje EDX, a 0x30 to offset jednego z jej pól). Wartość rejestru EDX natomiast została ustalona w [8]. Przyjrzyjmy się tej instrukcji:
Powoduje ona załadowanie do EDX wartości pod adresem, który teraz wskazuje. Taka konstrukcja w pętli jest często wykorzystywana jako iterator w algorytmach korzystających z list 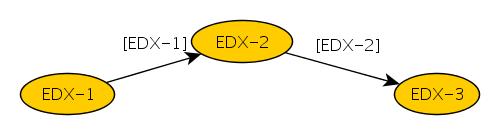 . A więc rejestr EDX może służyć w pętli loop_1 jako iterator elementów listy. Przed wejściem do pętli loop_1 jest on ładowany przez sekwencję operacji [1], [2], [3], a następnie zachowywany w EBX. Aby zrozumieć, jakiego rodzaju struktury są wykorzystywane w omawianym algorytmie, zacznijmy od pierwszej instrukcji:
. A więc rejestr EDX może służyć w pętli loop_1 jako iterator elementów listy. Przed wejściem do pętli loop_1 jest on ładowany przez sekwencję operacji [1], [2], [3], a następnie zachowywany w EBX. Aby zrozumieć, jakiego rodzaju struktury są wykorzystywane w omawianym algorytmie, zacznijmy od pierwszej instrukcji:
Powoduje ona załadowanie do EDX wartości z pod adresu 0x30 w segmencie pamięci wskazywanym przez rejestr segmentowy FS (dokładniej: selektor załadowany do rejestru FS). W aplikacji systemu Windows rejestr FS wskazuje na strukturę systemową TIB (Thread Information Block). Jak można sprawdzić, wartość 0x30 wskazuje na kolejną strukturę – PEB (Process Environment Block). Została ona zdefiniowana w pliku winternl.h następująco:
BYTE Reserved1[2];
BYTE BeingDebugged;
BYTE Reserved2[1];
PVOID Reserved3[2];
PPEB_LDR_DATA Ldr;
PRTL_USER_PROCESS_PARAMETERS ProcessParameters;
BYTE Reserved4[104];
PVOID Reserved5[52];
PPS_POST_PROCESS_INIT_ROUTINE PostProcessInitRoutine;
BYTE Reserved6[128];
PVOID Reserved7[1];
ULONG SessionId;
} PEB, *PPEB;
Oto poszukiwane przez nas środowisko wykonania, które może zostać zmodyfikowane przez debugger i wprowadzić błąd (np. znaczenia pola BeingDebugged nie trzeba chyba wyjaśniać =)). W linii [2] do rejestru EDX ładowana jest zawartość z przesunięcia 0x0C względem początku struktury. Można wyznaczyć, że przesunięcie to wypada na pole Ldr: dwa bajty na Reserved1, jeden bajt na BeingDebugged, jeden bajt na Reserved2, dwa razy cztery bajty na Reserved3 – razem dwanaście (0x0C) bajtów. Pole Ldr wskazuje na strukturę typu PPEB_LDR_DATA. Oto jej definicja:
{
ULONG Length;
UCHAR Initialized;
PVOID SsHandle;
LIST_ENTRY InLoadOrderModuleList;
LIST_ENTRY InMemoryOrderModuleList;
LIST_ENTRY InInitializationOrderModuleList;
PVOID EntryInProgress;
} PEB_LDR_DATA, *PPEB_LDR_DATA;
W linijce [3] do EDX ładowana jest zawartość pola InLoadOrderModuleList, które jest typu LIST_ENTRY.
Definicja LIST_ENTRY:
struct _LIST_ENTRY *Flink;
struct _LIST_ENTRY *Blink;
} LIST_ENTRY, *PLIST_ENTRY, *RESTRICTED_POINTER PRLIST_ENTRY;
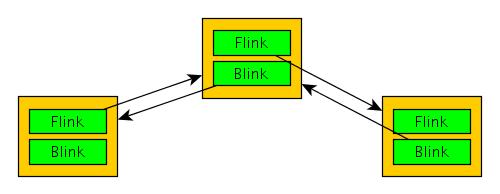
A więc, EDX wskazuje na pole Flink struktury LIST_ENTRY. Pole to wskazuje na następny element powiązanej listy cyklicznej LIST_ENTRY. Następny element jest ładowany przez skopiowanie tej wartości do EDX, czyli, jak już wspomnieliśmy, za pomocą instrukcji:
Wskaźnik na pierwszy element jest zachowywany do rejestru EBX w [4]. W pętli loop_1 program przegląda po kolei elementy listy i porównuje kolejne wskaźniki ze wskaźnikiem na pierwszy element. W ten sposób, kiedy lista się skończy, a EDX znowu wskaże pierwszy element, pętla zostanie przerwana w [8].
Dobrze, program przegląda listę elementów LIST_ENTRY. Ale przecież elementy te zawierają jedynie wskaźniki na następny i poprzedni element, nic więcej. W jakim celu więc to robią? Lista taka jest elementem pewnej konstrukcji, którą developerzy systemu Windows stosują przy tworzeniu list obiektów systemowych w wielu miejscach systemu (np. do organizowania stuktur opisujących listy sterowników). Poniżej przedstawiamy, jak ta konstrukcja jest stosowana.
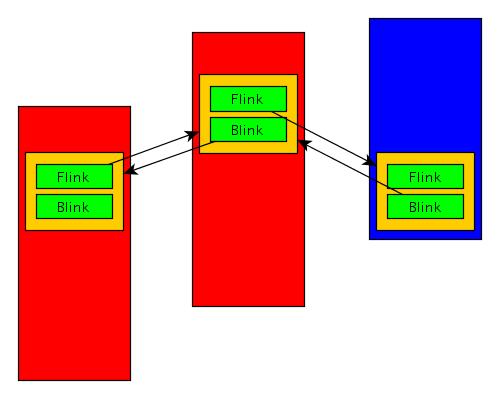
Elementy typu LIST_ENTRY są umieszczane wewnątrz struktur, które organizują (w przeciwieństwie do bardziej popularnego podejścia umieszczania w elementach listy wskaźników do struktur). Jest to mało intuicyjne podejście (a co za tym idzie, często jest przyczyną developerskich błędów, o czym przekonamy się za chwilę), jednak znacznie upraszcza cały mechanizm. Znając jeden ze wskaźników elementu LIST_ENTRY i znając definicję struktury, w której został on umieszczony, program, który chce uzyskać dostęp do któregoś z jej pól może zastosować prostą arytmetykę wskaźników, aby je znaleźć. Struktura, w której umieszczony jest nasz element LIST_ENTRY to LDR_MODULE:
{
LIST_ENTRY InLoadOrderModuleList;
LIST_ENTRY InMemoryOrderModuleList;
LIST_ENTRY InInitializationOrderModuleList;
PVOID BaseAddress;
PVOID EntryPoint;
ULONG SizeOfImage;
UNICODE_STRING FullDllName;
UNICODE_STRING BaseDllName;
ULONG Flags;
SHORT LoadCount;
SHORT TlsIndex;
LIST_ENTRY HashTableEntry;
ULONG TimeDateStamp;
} LDR_MODULE, *PLDR_MODULE;
A więc w każdej iteracji pętli loop_1 wykonujemy operacje na elementach o strukturze LDR_MODULE. W szczególności odwołujemy się do pola o przesunięciu 0x30 [5].
Każdy element LIST_ENTRY zajmuje dwa razy cztery bajty, czyli razem 0x08. Pierwsze trzy pola zajmują razem 0x18 bajtów. Pole BaseAddress i EntryPoint to kolejne 0x08 bajtów. SizeOfImage zajmuje 0x04 bajty. Następne pole zawiera strukturę:
USHORT Length;
USHORT MaximumLength;
PWSTR Buffer;
} UNICODE_STRING;
Dwa pierwsze pola zajmują razem 0x08 bajtów, a Buffer – 0x04. A więc w [5] do ESI jest ładowana wartość pola Buffer drugiej struktury UNICODE_STRING. W instrukcji języka C ta operacja mogłaby mieć postać:
PWSTR myBuffer = pModule->BaseDllName->Buffer;
Następnie, w [6] program próbuje odczytać tą wartość i w pewnym momencie wykonania generuje wyjątek AccessViolation. Dlaczego więc w polu Buffer znajduje się nieprawidłowa wartość?
Dlatego, że struktura, w której znajduje się aktualnie załadowany element LIST_ENTRY nie jest typu LDR_MODULE =). Jeden z elementów znajduje się w PEB_LDR_DATA 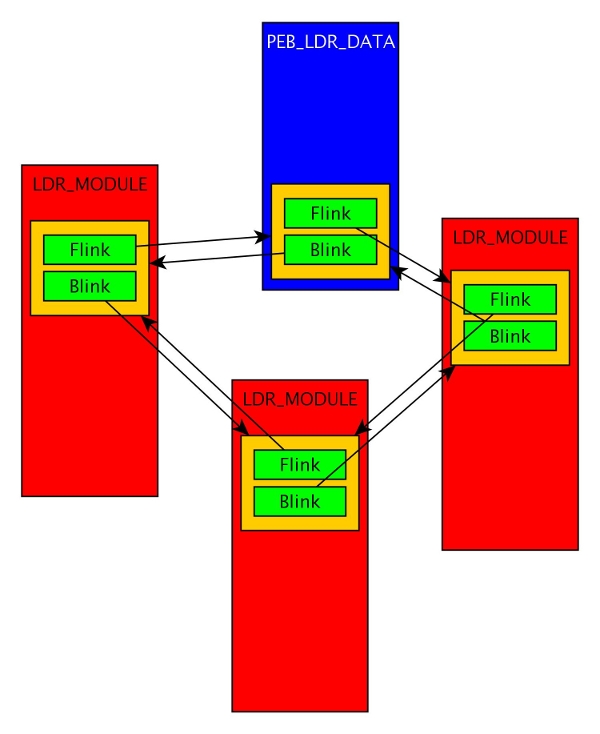 . Odwołując się do tego pola programista popełnia błąd (mowiliśmy, że ta konstrukcja jest nieintuicyjna? =)). Cokolwiek znajduje się 0x30 bajtów za początkiem struktury PEB_LDR_DATA raczej nie jest ani składnikiem struktury LDR_MODULE ani wskaźnikiem do łańcucha znaków.
. Odwołując się do tego pola programista popełnia błąd (mowiliśmy, że ta konstrukcja jest nieintuicyjna? =)). Cokolwiek znajduje się 0x30 bajtów za początkiem struktury PEB_LDR_DATA raczej nie jest ani składnikiem struktury LDR_MODULE ani wskaźnikiem do łańcucha znaków.
A więc w algorytmie zaimplementowanym w bocie Kelihos.B znajduje się błąd. Dlaczego jednak czasem wywołuje on wyjątek, który kończy pracę aplikacji, a czasem – nie? Aby odpowiedzieć na to pytanie, musimy powrócić do punktu wyjścia i zadać inne: jaka jest natura zmian wprowadzanych do środowiska wykonania programu przez debugger, które sprawiają, że błąd ten jest powodem zakończenia aplikacji? Oto odpowiedź.
Jeśli program został uruchomiony z podłączonym do niego debuggerem (czyli ze zmienionym środowiskiem uruchomieniowym), uruchamiane są też mechanizmy analizy sterty. Mechanizmy te (nie będziemy ich opisywać w tym artykule) ułatwiają wykrywanie różnych błędów, między innymi przepełnień. Jedną z oznak tego faktu (a co za tym idzie, oznaką obecności debuggera) jest dodanie do wybranych miejsc pamięci ciągów heksadecymalnych: 0xABABABAB oraz 0xFEFEFEFE. Powoduje to zmianę przesunięć pomiędzy niektórymi z umieszczonych w pamięci struktur. Błędne odwołanie do pola Buffer w [6] bez tych przesunięć powoduje załadowanie do rejestrów innych wartości, niż z nimi. W efekcie, jeśli program jest uruchomiony bez debuggera, rejestr ESI zawiera jeden ze wskaźników struktury LDR_MODULE, natomiast jeśli jest uruchomiony bez debuggera – zawiera nieokreśloną bliżej wartość, która nie wskazuje poprawnej wartości w pamięci (tak jak w przykładzie z odwołaniem do adresu 0), więc wywołuje wyjątek kończący pracę programu.
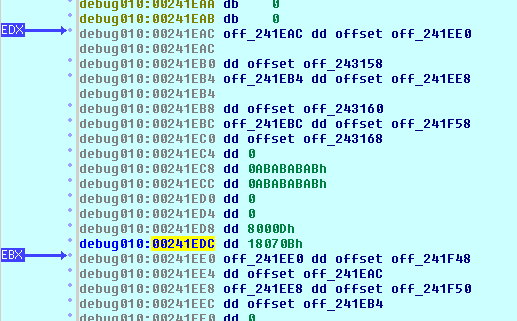
Aby sprawdzić, czy nasze przypuszczenia są słuszne, przed wykonaniem instrukcji generującej wyjątek można zapisać do rejestru ESI dowolną wartość wskazującą poprawny adres w pamięci procesu. Program będzie kontynuował swoje wykonanie, zdeobfuskuje swój kod i przystąpi do wykonywania swoich głównych funkcji – komunikacji z innymi węzłami sieci P2P oraz serwerami CC. Można także przed uruchomieniem debuggera ustawić zmienną środowiskową _NO_DEBUG_HEAP, która wyłącza opisywane mechanizmy.
Podsumowanie
Podsumujmy wyniki naszych badań. Zabezpieczenie analizowanej próbki polega na zastosowaniu błędnego algorytmu przeglądającego listę struktur systemowych – załadowanych przez proces modułów. Popularny błąd został wykorzystany do uzależnienia wykonania zabezpieczonego kodu bota od obecności debuggera. Zamiast prostego sprawdzenia obecności łańcuchów 0xABABABAB i 0xFEFEFEFE, które zostałoby szybko zidentyfikowane przez analityka jako test na obecność debuggera, autor zabezpieczenia wykorzystał błędny algorytm i jego dużą wrażliwość na zmiany w środowisku, które wprowadza debugger. Jest to bardzo subtelne i innowacyjne podejście, które może przez długi czas skutecznie opierać się analizie wstecznej. Na szczęście udało się je w końcu przełamać i kontynuować analizę Kelihos.B. Dalszymi wynikami podzielimy się w kolejnych publikacjach na naszej stronie.
